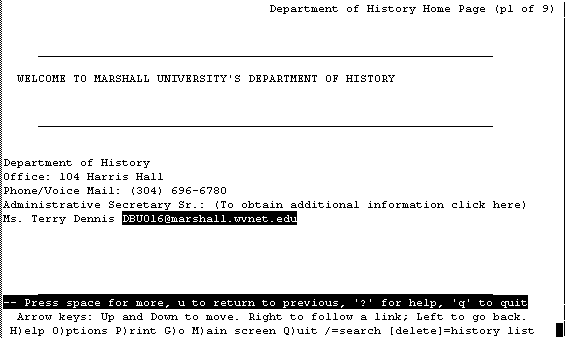
An early text-based Web browser
Christopher (Cal) Lee
University of Michigan
School of Information
The popular media were soon describing Gopher as an obsolete predecessor to the Web, rather than one of the protocols available along with Hypertext Transfer Protocol (HTTP) through most browsers. By juxtaposing today's Web with today's Gopher, it is easy to come to a technologically determinist conclusion about the reason for Gopher's seeming demise. Searching the Web through an engine like Alta Vista using Netscape Communicator 4.5 or Microsoft Internet Explorer 5.0, for example, is much more effective in most cases than trying to conduct the same search in Gopherspace through that same browser or even using a dedicated Gopher client. But the current technological situation was not inevitable. The superiority of the early text-based Web over its Gopherspace contemporary was by no means obvious.
I investigate potential explanations for the rise and fall of Gopher. Why is Gopher not commonly used as a protocol for corporate intranets? Why have most libraries abandoned their efforts to maintain a presence in Gopherspace? Why have so few people heard of HyperGopher or Gopher+, yet the popular technology press makes front-page news out of almost every minute advancement related to Web browsers, HTTP and HTML? In an attempt to provide at least partial answers to these questions, I use Requests for Comments (RFCs), project documents (such as FAQs and publicly posted email messages), and published interviews with the developers of both HTTP and Gopher; and popular literature (information science professional magazines and journals being heavily represented) from 1991 to the present that reflects the media's position on Gopher.
I explain the relationship between Gopher and the Web in terms of their "mind share." This is a phrase that has recently come into use within discussions of electronic commerce and online services. In contrast to market share, which measures how many people are buying a firm's products or services, mind share represents how strong a presence those products or services have in the minds of consumers. As I interpret it, mind share can be seen as a superset of the long-standing concept of "branding," which recognizes that products with a well-recognized name (e.g. CocaCola) are worth more than lesser-known products, even if the products themselves are objectively of equal value.
In addition to brand name, many other intangible factors can make up a product's or service's mind share advantage. A Web portal, for example, that can "get more eyeballs" than its competitors is said to have a mind share advantage. This could take the form of name recognition, URL recognition, use by many people as the default "home page" when exploring the Internet, presence in many people's bookmark lists, links from other Web sites, references in other popular media, and technological interoperability with other popular online resources. In psychological terms, mind share can be roughly defined as the attentional resources a product or service has at its disposal. While there is a great deal of debate about whether or not such mind share can actually translate into profitability over time [Wilson], the phenomenon itself is widely recognized. It is often difficult to pin down the specific reasons why one Web site, company, technology or system manages to gain mind share while others lose it. This paper will first lay out the story of Gopher's rapid gain and loss of mind share, and then explore some reasons why this may have occurred.
| Protocol Name | Date | Purpose |
| Telnet | 1969 | Largely a proof of concept for the ARPANET project. Allowed users to remotely emulate the terminal of another computer. |
| Network Control Protocol (NCP) | 1969 | Allowed sharing of resources between computers that went beyond simple terminal emulation. |
| File Transfer Protocol (FTP) | 1972 | Files could be shared remotely. |
| Transmission Control Protocol (TCP) | 1975 | Allowed resource sharing between networks other than the ARPANET. |
| Internet Protocol (IP) | 1978 | Separated some of the networking functionality (e.g. transfer acknowledgment) from the simple act of passing packets. |
TCP/IP was official adopted by the ARPANET in January of 1983 in order to allow interchange between the ARPANET and other networks around the world. As with protocols used in human negotiations, the development and selection of protocols for information interchange between computers often turns political, as in the email "header wars" that took place in 1975 and those between TCP/IP and OSI in the 1980s. [Hafner and Lyon]
After the above protocols were well established, allowing efficient
and reliable interchange between heterogenous computing environments, a
further step was to make this interchange understandable to less techno-savvy
end users. A major advance in this direction was distributed filing,
which allowed users in various locations, using various computer platforms
to share a common file structure for interchange. The Network Filing
System (NFS), developed in 1984 by Sun Microsystems, was designed as a
distributed file system to provide "transparent" file services between
heterogeneous UNIX environments. It allowed users to mount remote
directories and disks so that they appeared as local drives, so that they
could share access to both files and printers. [Digital
Equipment Corporation]
The Andrew File System (AFS) was a similar system, developed by Carnegie
Mellon University the same year. It was used to provide a campus-wide file
system for home directories which would run effectively using a limited
bandwidth campus backbone network. In 1989, the Transarc company
was formed to evolve the Andrew File System into a commercial product.
Networked filing systems, however, still required a user to understand and navigate the filing system of the network. This imposed a considerable burden, not only because file hierarchies are a limited tool for resource discovery (a file can generally be put in only one place), but also because the people who set up the file hierarchies were generally experienced computer administrators, who organized resources in a way that was often confusing to an inexperienced user. In 1990, Alan Emtage at McGill University in Montreal invented Archie, which helped to address these concerns. Archie searched and indexed files that were available on the Internet through FTP. This was a major boon for users. Instead of having to identify the FTP site that might be appropriate and then negotiate its file structure, they could query the Archie index to look for files of interest. Archie made the identification of useful files much easier, but it still had some serious limitations. Not only were files indexed by file name, which was often uninformative, but users still needed to know how to deal with FTP directories and client software once they decided to retrieve the files they had identified through Archie.
The development of Gopher was a local response to this general problem. In 1991, the University of Minnesota wanted a simple menu system to provide access to files and information on campus through their local network. A debate followed between those advocating a mainframe model and those who preferred a client-server architecture. The mainframe adherents were winning the debate initially, but the client-server advocates said they could develop a prototype much more quickly and they were given the go-ahead to do so. Bob Alberti, Farhad Anklesaria, Paul Linder, Mark MacCahill and Daniel Torry at the Microcomputer and Workstation Networks Center unleashed Gopher (named after the University of Minnesota mascot, the Golden Gopher) on the world later that same year. The system was composed of server software, client software and the protocol that allowed the two to communicate.
Users could have a Gopher client application running on their own computer
or use Telnet to log into a server, then use the Gopher client program
that resided on that server. At first there were two types of files,
menus and text documents. The menus were also ASCII text files but
they conformed to a specific comma-delimited format. They provided
pointers to documents, other menus, or services (such as WAIS) that allowed
for text-based searching. This architecture allowed users to browse
up and down the hierarchy of files, looking for files that interested them. Like all other Internet clients of the time, Gopher had a command line interface, using arrow keys and characters to represent functions. Generally, / at end of line meant another menu, period meant text file,
<TEL> meant Telnet session and <?> meant a searchable database. Many additional key commands were also available, but varied greatly from one client to another.
| Internet Gopher Information Client v1.12
Root gopher server: gopher.tc.umn.edu --> 1. Information About Gopher/
Press ? for Help, q to Quit, u to go up a menu
Page:1/1
|
One of the greats appeals of Gopher was that an end user did not have to know about the nuts and bolts of the protocol in order to navigate effectively. The other protocols and tools mentioned above made important steps in this direction, by allowing organizations to share files between platforms and without regard to specific computer architectures, but they still required a familiarity with the directory structure and the tools (generally FTP and Telnet) used to negotiate it. Gopher took transparency to a higher level, since visitors to a Gopher site did not need to know the specific file name or even the host and path name on the computer where a file was located in order to retrieve it. One would simply type or click on a number to select the menu he or she wanted, and Gopher would take care of dealing with the details of computer architecture. Not only were the barriers to entry very low in terms of learning the system, but they were also quite low technologically. Both the client and server software were compact and easy enough to install that a wide range of computer users could begin to use the Internet, who had previously found it too intimidating, time consuming, or expensive. What began as a Campus Wide Information System (CWIS) soon became Gopherspace, a virtual realm visited by thousands of people around the world.
In 1990, the year before Gopher got started, Conseil Européen pour la Recherche Nucléaire (CERN) in Geneva, Switzerland developed and began to use a system it called the "World Wide Web." It also allowed for search and retrieval of files across a heterogenous network, but it was based on a different information architecture (more on this later).
An early text-based Web browser
The adoption of the Web quickly became international. In 1991, the Stanford Linear Accelerator Center (SLAC) in California became the first Web server in the United States. The Hypertext'91 conference that was held soon after in San Antonio, TX, further advanced the Web development cause.
In 1992, the Gopher development community had a conference of its own, GopherCon'92. Many new ideas and implementations were presented and shared. There was talk already of improving on Gopher through a version called Gopher+. [Riddle] This new version of the Gopher protocol, which allowed for additional file types and attributes, including multiple views of the same document, was implemented soon after the conference.
Gopher's usability was enhanced significantly on November 17, 1992, when Steven Foster and Fred Barrie at the University of Nevada at Reno released a tool called Veronica (Very Easy Rodent-Oriented Net-wide Index to Computerized Archives). Much as Archie did for FTP, Veronica provided a searchable index of Gopher menus. A spider crawled around Gopher menus all over the world, collecting links and retrieving them for the index. It became so popular that it quickly became very difficult to connect to Veronica, despite a number of other sites being developed to ease the load. In 1993, Rhett "Jonzy" Jones at the University of Utah invented Jughead (Jonzy's Universal Gopher Hierarchy Excavation and Display). This tool was similar to Veronica, except that it indexed single sites, instead of all Gopherspace. (Peter Deutsch, who developed Archie, insisted its name was short for Archiver, and had nothing to do with the comic strip. He was supposedly disgusted when Veronica and Jughead appeared.) [Howe, "A Brief History"]
Not only did the infrastructure of Gopherspace improve dramatically in its early years, but the Gopher clients used to view and navigate Gopherspace also became much more user-friendly. Functionality such as bookmarking was improved, graphic user interfaces (GUIs) were released, and there was even a client called TurboGopherVR that allowed users to search gopher space through a 3-dimensional interface.
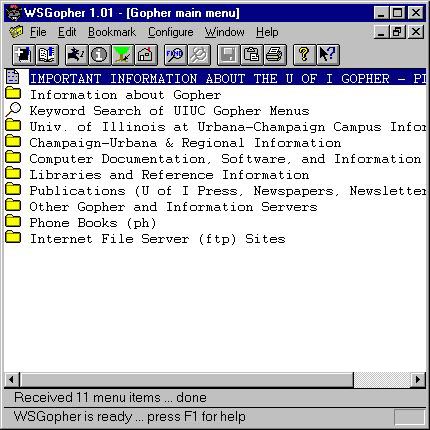
A Gopher Client available in 1994
The annual growth rate for Gopher traffic in 1993 was 997%. * [Treese, II1] Libraries, campuses and even some companies began to jump on the Gopher band wagon. Setting up a Gopher server was seen by many as the easiest and most effective way to establish a niche on the Internet. By April of 1994, the number of known Gopher servers had reached 6958. [Treese, II2]
Then Mosaic entered the picture. Marc Andreessen and Eric Bina posted the Unix version of Mosaic to NCSA's servers in the winter of 1993 "and it spread like a virus after that," (9) [Reid] with 1600 copies being downloaded per day by 1994. [Treese, II2] In January of 1993, just before Mosaic's release, the Web was .002% of backbone packet traffic, ranked 127th largest source of traffic. By June, it was in 21st place with .25%. By September, it had reached 16th place, with Gopher still ahead in 10th place and FTP in first. (16) [Reid] Annual rate of growth for WWW traffic in 1993 was 341,634% [Treese, II1]
In 1994, the First International WWW Conference was held in Geneva, at CERN. It attracted more than 600 Web enthusiasts, only 400 of which could be admitted and was dubbed the "Woodstock of the Web." [Cailliau] The Second WWW Conference was by NCSA in Chicago and attracted 1800 people, of which only 1300 can be admitted. Tim Berners-Lee and the Laboratory for Computer Science (LCS) of MIT (Massachusetts Institute of Technology) soon set up the W3C Consortium in the US.
Different sources of data on Internet traffic during this period [Treese, II2] [Pitkow, "Third Degree"] [Treese, II5] [Pitkow, "Relation"] [Treese, II22] [GVU] [Treese, II7] provide somewhat different numbers, but they all describe the same general trend: both the WWW and Gopher continued to grow, but at quickly diverging rates. By some time around the middle of 1994 (depending on whom you ask), WWW growth shot far ahead of Gopher growth. Within a few months after this split, Gopher traffic actually began to decrease. In addition to these trends in traffic, the number of links to the different types of servers also changed dramatically. Between the spring and fall of 1995, links to servers other than WWW servers (FTP, Gopher, etc.) were down, indicating to many people that these non-WWW services "may very well become legacy services." [Pitkow and Recker, 4th]
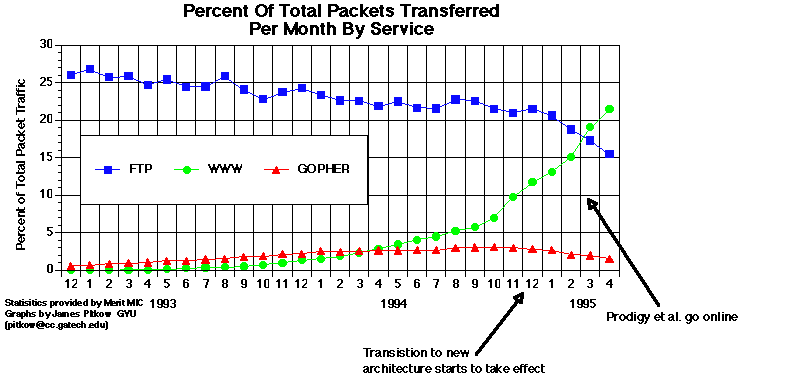
The years 1993 and 1994 also saw numerous advances in indexing and search engine technology and availability. [Sonnenreich] These engines made the Web much more usable and often neglected Gopherspace. This had a recursive effect. As the Web became easier to use and more content-rich, traffic grew. As traffic grew, content providers had more incentive to invest in the Web. By early 1995, Lycos had indexed 3.6 million pages on 23,550 different Web servers.[Treese, II7]
As the popular media constantly remind us, the astronomical growth of the Web continues to this day. Gopher, on the other hand, has largely dropped out of the picture. The Usenet newsgroups dedicated to discussions about Gopher have very little traffic, with most recent messages either lamenting the loss of Gopher or lampooning it as a useless technology. A large proportion of Gopher servers have either been taken down or remain simply to point users to the Web. Gopherspace is littered with messages like the following:
The University of Houston Libraries Gopher is no longer being
maintained. Many of the resources that were here, plus much
more, are available through the University of Houston Libraries
Web Server at http://info.lib.uh.edu [University of Houston Gopher].
Even the University of Minnesota's own Gopher server [University of Minnesota Gopher] is showing signs of decay. It is still maintained, but content is a bit lacking and the Veronica server is no longer operational. Gopher, it would seem, is simply no longer a viable option for Internet development, use or information delivery.
One might ask what caused such a radical rise and fall in such a brief period, or, as one author bluntly asks, "Who Killed Gopher?" [Khare]
One common explanation of Gopher's demise is that it does not support hypertext, which is what the Internet really should be providing. Without hyperlinks, this argument goes, Gopher is little more than an electronic filing system. The Web, on the other hand, makes great use of hypertext. In order to discuss this position, it is helpful to get a better idea of what exactly hypertext is.
In 1945 Vannevar Bush, science adviser to President Roosevelt, wrote
a now famous article in the Atlantic Monthly about what he called
the "Memex," a device (based on microfilm) for storing vast amounts of
documents in a single workspace, with tools for finding, organizing and
adding to the repository. [Bush]
This vision of the memex inspired many later developers. It served
as an ideal toward which information technology system developers could
strive.
In the 1960s, Douglas Engelbart produced the first real hypertext system. He and people like Joseph Licklider aimed to use computers to augment human intelligence through the effective manipulation of information. In 1968, Ted Nelson coined the term "hypertext," which is now in common use. Nelson laid out project Xanadu in 1981, which was a bit like a networked version of the Memex.
Both Gopher and the Web embraced the idea of hypertext. Both allowed users to follow a conceptual path through a virtual space by following links, with little need to understand the structure that existed underneath. They differed considerably, however, in the information architecture that they established for laying out hyperlinked information. The main difference between the two is that the HyperText Transfer Protocol (HTTP) of the Web was built up around documents in HyperText Markup Language (HTML). This markup language allowed document creators to place links within documents, whereas Gopher provided pointers to documents through menu files, which existed separate from the documents themselves. The indexing component of the two information architectures -- i.e. the part that enumerated what items existed within the information space and where they could be found -- thus differed considerably.
The Gopher model assumed a higher number of system administrators, with low entry costs, to carry out the indexing of files by creating Gopher menu files that pointed to all the files on a Gopher server (and often other servers). The Web, on the other hand, assumed fewer system administrators, with higher entry costs, who were not required to maintain any sort of index files but instead left that up to the content authors, who were responsible for creating pointers within the pages they created. This distinction is often misunderstood, with many articles describing Gopher in its opposition to hypertext, instead of recognizing that it is a form of hypertext that is based on external versus internal indexing.
If we speculate about the counterfactual world in which Gopher beat the Web for mind share, then it seems the Internet could have moved to a model in which server administrators were responsible for creating menu files and identifying and fixing outdated links (most likely by hand and then automatically as they developed the tools), while authors would be free to post files to Gopherspace at will. The division of labor would be quite different from how it currently stands, with server administration being less about system configuration and maintenance (which would be less complicated) and more about intellectual control (which would be more complicated). In many ways, link checking and organizing would actually be much easier to automate than it currently is, since it would be more centralized. There would still be distributed administration and link rot issues but it would be a different model for the relationship between content and structure, not markup but rather a large number of tab delimited ASCII databases. This Web has actually begun to move in the direction recently, with many Web sites providing their own search engines based on their own inverted files on the server.
Technical inferiority to Mosaic
Apart from the information architecture, one of the most common explanations of the Web's victory over Gopher is that Mosaic was just a much better interface than any existing Gopher clients. It included a cleaner GUI, viewing images within the text of documents, a back button that allowed one to return to a page that had just been visited, among other features. In January of 1994, user survey respondents showed a strong preference for using a Web browser for Internet exploration, instead of relying on specific clients like Gopher or WAIS. [Pitkow and Recker, 1st] and this continued to be the case in three more surveys in the following two years. [Pitkow and Recker, 3rd], [Pitkow and Recker, 4th], [Pitkow and Recker, 5th] One would naturally assume that this is largely based on the types of features introduced by Mosaic.
Mosaic was also a "super client," in that one could use it to navigate over a number of protocols, including FTP, HTTP and Gopher. End users preferred this to the modular Gopher approach, which assumed that tools should be small, compact and self-standing, allowing users to mix and match just the functions they most wanted. Non-technical users, however, did not want to be bothered with such decisions. There are many examples of this phenomenon, including the popularity of software that has been bundled into suites of applications and integrating previously separate applications into the operating system. It is important to remember, however, that the Web was not synonymous with Mosaic. Not only could Mosaic be used to search Gopherspace, but many of the features Mosaic boasted were also soon available on Gopher clients.
Web's superior infrastructure
The Internet's capacity to serve the needs of Web users quickly became much better than that for Gopher users. One clear example is Veronica and Jughead, which allowed indexing of titles only, no full-text searching. Another major complaint about Veronica was slow access. This was not based as much on the technology itself as it was on a lack of buy-in leading to infrastructure. For a long time, there were only two Veronica servers.
Though there are some who argue that Gopher failed simply because it was not as extensible as the HTTP protocol, [Khare] I see this as only a small part of the story. The major issue was not the original configuration of the protocol but instead the fact that it did not become a test bed. Mind share moved from Gopher to the Web, leaving only a handful of developers at the University of Minnesota and a few other places to tweak Gopher to meet a rapidly increasing demand and level of expectations.
Cheaper computing resources
Increased computing resources clearly reduced the need for a bare-bones
protocol and software. It is for this reason that Gopher was soon
explained as an option primarily for poor institutions that have not had
the opportunity to catch up with technology or government agencies who
are mandated to serve all types of users, even those with text-only terminals.
[Serdar] This begs the question, of course, of why more features were not built
into Gopher to make up for this shift in demand. The story I provide
in the following section attempts to explain why this was not the case.
The importance of these factors is reinforced by posing a simple counterfactual question: What would have happened if all of the human resources (in development, content creation and user traffic) that were thrown at the Web in the early 1990s had instead been thrown at Gopher? Or stated in the terms of this paper: What would Gopher be like today if it had captured the mind share that was instead captured by the Web?
A meaningful answer to this question cannot simply be derived from looking at the current state of technology and then drawing a rigid line of causation into the past. Using the current state of Gopherspace to argue for its technologically inevitable demise is tantamount to arguing for the obvious superiority of VHS over Beta by pointing out how much more selection of cassettes and players are currently available for the former format than the latter. There is clearly much more going on in that case than picture quality and storage capacity. Broad social trends, roughly what an economist would call "network externalities," play a significant part in the adoption of one technology over another. I contend that, much as one brand of blue jeans does not win over more consumers than another brand simply based on the comfort and durability of its material, the Web did not overshadow Gopher simply based on the technical qualities of HTTP as a protocol.
Social Inertia
An argument for social inertia is a rejection of pure technological determinism. As with the dominance of VHS over Beta or the QWERTY keyboard over other layouts, a lot of technological adoption is simply based on past adoption. Described systematically, this phenomenon has been labeled "spontaneous self-organization" [Waldrop], "autopoiesis" [Maturana and Varela] , or "accumulation of design" [Dennet]
In order for complex systems (like Gopher or the Web) to perpetuate themselves, they must strike the right balance between exploring new options and exploiting their past success. [Axelrod and Cohen] That is, they must make new advances to fill new niches that arise without changing so radically that they can no longer take advantage of their successful track record. The short answer to the questions posed in this paper is that the Web did this right, and Gopher did it wrong. Of course, claiming this is far different from being able to say exactly why Gopher failed, just as saying someone got checkmated does not provide the most fulfilling explanation for why someone lost a game of chess.
The literature on complex adaptive systems draws heavily from evolutionary theory in biology. On a smaller scale, it can be used to explain why certain technologies are adopted and others are not. Resistance to a technology can be seen as "a signal of the mismatch of expectations between users and designers" (33). "The analogy of evolution (mutation, selection, and retention) on technological change stipulates resistance as an external factor that selects products and processes over time. Retrospectively these appear as lines of progression. At the time the selection process is surprising and subject to attempts to gain control. Any present range of technical devices and ideas is the outcome of past resistance which works as a filter: screening out some items, letting through others, pushing the path of 'progress' into a particular direction. Technological development is at times gradual, at times it jumps from one 'punctuated equilibrium' to the other, depending on large-scale environmental events" (28) [Bauer]
On the positive side, i.e. not rejection of technologies but rather the adoption of ideas, the study of memetics can be very helpful. Memetics is the study of how "memes," ideas that act like the conceptual analog to genes in biology, perpetuate themselves over time. [Dawkins, Selfish Gene][Dawkins, Blind Watchmaker][Lynch] The idea that Gopher had been replaced by the Web, for example, can be explained in terms of the survival success of that idea as a meme. As the Web grew, the content it provided to users perpetuated the idea, both explicitly and implicitly, that it had made Gopher obsolete.
These explanations cannot tell the whole story, however, since they fail to address the question of what started the trend away from Gopher and toward the Web in the first place. Pure determinism, either technological or sociological, fails to account for or explain the activities carried out by specific individuals. [Misa] Though I find systematic explanations of technological trends useful in identifying the influences involved, I prefer an explanation that is more clearly grounded in the actions of specific individuals and organizations. The three interrelated factors that I have identified are institutional influence, publicity and open-systems participation.
Institutional influences
The Web had the advantage of coming out of CERN, which is the world's largest High-Energy Physics (HEP) laboratory. It is funded by 19 European member states and is located near Geneva, with facilities on both sides of the Swiss-French border. The Web was also in more of a position to fill the Internet's collaborative and international niche, since high-energy physics was a process, which required the sharing of information across boarders. Gopher, on the other hand, was started as a campus-wide information system (CWIS), which was largely based on getting access to local resources, like address books and library catalogs.
Mosaic also had the advantage of coming out of NCSA, where many eyes were looking for innovative developments (9). [Reid] NCSA was one of the 5 major super computing centers on the NSFNet and had created Telnet. Any product released by a project there automatically received attention. The same could not be said for the University of Minnesota, which was a well-respected academic institution, but not generally seen as a hotbed of computer innovation.
The Web was thus in a much better position, both socially and economically, to influence the future direction of the Internet.
Bad publicity
Public sentiment has a tendency to snowball around specific issues [MacKay]. Statements made in the public media have a strong influence on this process. As mentioned above, the Web also had the advantage of being a medium of expression itself. As more content flooded the Web, more material was either explicitly or implicitly lauding the virtues of the Web.
One factor that seems almost comical at first, but may actually have had a considerable effect on the mind share battle was the simple choice of names for the two projects. The developers at CERN decided on the "catchy name" World Wide Web before anyone outside of CERN was even using the system. [Cailliau] This name immediately brings to mind not only a global picture but one based on broad networks of interconnected elements. Gopher, on the other hand, was named after the University of Minnesota's mascot. Its name was an instant reminder of Gopher's local institutional origins. It was also often attributed to the protocols ability to allow users to burrow down into the informational hierarchy (as gophers burrow down into the earth) and the colloquial label of gopher for someone whose duty it is to go get things for his or her boss ("go fer this, go fer that"). Though both of these point out Gopher's useful ability to retrieve information for its users, neither one exactly brings forth images of cutting edge technology. If anything, they reminded one of the numerous cute and cuddly images of gophers that accompanied almost every article that discussed the protocol.
This points out the much more general issue of the Web's advocates describing it as a diverse global network of idea exchange and Gopher's advocates generally describing it as a useful CWIS based on familiar metaphors, such as FTP and the filing system of common operating systems. The rhetoric of the two groups became largely what Donald MacKenzie calls a "self-fulfilling prophecy." [MacKenzie] They defined the niche, and the technology then proceeded to fill it.
The following NCSA statement from 1993 clearly demonstrates the effective rhetoric put forth on the part of the Web:
NCSA is currently developing a new software tool, NCSA Mosaic, that will encompass all of the currently used global information systems and provide greatly increased functionality and ease of access to the Internet-based universal information space. NCSA Mosaic is a distributed hypermedia information system based on the World Wide Web technology originated by CERN. Mosaic provides a unified, coherent, hypermedia-based portal to the expanding Internet information space by enabling transparent access to all of the major information systems currently in use on the network (Gopher, WAIS, anonymous FTP, Archie, Usenet news, etc.). By virtue of its World Wide Web basis, Mosaic also provides a unique, flexible and important networked information functionality not available in other existing systems -- distributed hypermedia. In addition, Mosaic provides user- and community-level annotation and hyperlink support for collaborative work based on information accessible on the network. Mosaic is being developed across the X Window System, Macintosh and Microsoft Windows environments. Mosaic was originally conceived as an asynchronous collaboration system -- an environment for geographically distributed group or community members to operate on a common networked information base as part of their everyday work Current and future development will focus on enabling and expanding capabilities for information sharing, collaborative navigation and local information space construction across the global information space. Mosaic already supports extensive local information space customization methods, including text and audio annotations that can be attached transparently to any document available from any information source on the Internet. Future efforts will evolve this into a general system for sharing annotation, hyperlink, and document and information space construction activities across small and large groups and communities alike. As a result of these efforts, Mosaic and the Internet will become a flexible, malleable, and extensible information and collaboration system for a wide variety of uses by a large number of people, both independently and in groups and organizations. [Wilson and Mittelhauser]The rhetoric of Mosaic as a "killer app" was also much more appealing than either HTTP or Gopher as a "killer protocol," even though the latter is more accurate. Gopher was increasingly seen and described as the client software and not the protocol, thus Mosaic was a replacement, not just a browsers that could handle multiple protocols through a GUI. Since users tend to only recognize features, not the back end that makes them possible, Mosaic was naturally associated with both the Web and the GUI, leaving users to see Gopher as the "app" of yesterday.
Coverage in the popular media changed dramatically during the rise and fall of Gopher. Though it is difficult to determine which had more influence upon the other, the rise and fall of support for Gopher in the media matches up very closely with the rise and fall of its Internet traffic. In March 1993, one author stated, "Using client software on your local
computer you can move around the Gopher environment via a hierarchical
menu system in a seamless fashion." "Judging by the speed with which this
Gopher resource discovery technology is being adopted, it will surely become
a widespread method of access in the future" (53). [Simmonds]
Such accounts were quickly overshadowed, however, by claims such as
the one in December of 1993 by The New York Times that Mosaic
was "an application so different and so obviously useful that it can create
a new industry from scratch" (17). [Reid]
By February of 1994, readers were told, "While the Gopher system is probably at the peak of its popularity, the World Wide Web (WWW or W3) is now gaining in popularity as a system for publishing electronic information" (59). Gopher is "extremely easy to use and not difficult to maintain" but "poorly documented" (65) and the "menu system is very restrictive" and lacks support for URLs. Thus "Gopher will eventually become merely another information resource accessible by the World Wide Web." "Gopher is established, and is unlikely to change. World Wide Web, while supporting access to all of the existing electronic resource types, is a new frontier. Libraries may present information in any way they like." "This system is so versatile and configurable that the only boundary is the author's imagination" (66). [Powell] The New Hacker's Dictionary also stated in 1994 that Gopher was "being obsolesced by the World Wide Web." [Raymond] In a 1995 book, Gopher was described as "another extension to ftp" (230) [Salus]. August 1995 source explained, "After the development of WWW (and the WWW browsers), Gopher became somewhat obsolete. Today, more than 70% of the gopher menus are also provided as WWW pages." [Serdar] In a popular book published in 1996 on the history of computers, Gopher is only peripherally mentioned as a stepping stone toward the Web, which is the current contender for becoming the "world brain" that so many theorists have dreamed about (297-8). [Campbell-Kelly and Aspray]
With a very few exceptions [Hansen], later documentation of Gopher describes it as a technological has-been, making statements like the following:
An open systems model can take on two different but very interrelated parts: open communications standards and open source software. The two work best when implemented together [Stoltz]. In both cases, the Web development team did a better job than did the Gopher team.
Successful open-source development can be understood by Richard Gabriel's claim that "the right thing" design approach, tends to lose to "worse is better." [Gabriel] That is, developers should release their software to the public early in the process in order to gain adherents and then let a larger development community make improvements to the code. The Gopher team put too much burden on themselves for providing innovations to the protocol, servers software, etc. They decided that they would decide what the "right thing" was, instead of unleashing these decisions on others.
This had the practical shortcoming of significantly reducing the number of people who could be working to make necessary changes to Gopher. Open-source software advocates such as Eric Raymond explain that opening up a development effort has profound human resources advantages over a more centralized approach. Not only will users of any successful computer technology always outnumber the people who created it, but they also have a strong incentive to make improvements to the tools that they themselves use regularly. [Raymond, "Cathedral"]
In addition to these practical concerns, there was also a political
element to open-source software development, represented by such spokesmen
as Richard Stallman. In 1983, Stallman founded the GNU (GNU's Not
Unix) Project and wrote the "GNU Manifesto" to justify and gain support
for his development of a free Unix-compatible operating system. In
it, he stated, "I cannot in good conscience sign a nondisclosure agreement
or a software license agreement."
[Stallman]
Such arguments had significant support in the hacker community, and when word got out that Gopher would require the payment of a licensing fee for hosts with a .com domain but not those with an .edu domain, there were many developers who were turned off by Gopher. This licensing controversy sent the message of rejecting the open-source model. The issue was more than just being "commercial" (as were Archie, WAIS, Mosaic, and other tools) but rather not being open during the development phase for the protocol. This was a violation of the hacker ethic. [Raymond, "How to"] [Levy] Not that they were attempting to make money off Gopher but rather that they were violating the trust of those who would like to use and tinker with the code by creating an artificial line in the sand between educational and commercial uses.Tim Berners-Lee attributes this turn of events with a lot of weight in development of the two protocols: "The Internet Gopher was seen for a long time as a preferable information system, avoiding the complexities of HTML, but rumors of the technology being licensable provoked a general re-evaluation." [Berners-Lee, August 1996]
By failing to bring developers under its fold, the Gopher project fell victim to what is often referred to as forking, i.e. splintering into many options instead of settling on one standard approach. Forking can be effective, but only after enough support has been created that the forked technology can stand on its own, without the help of those working on the technology from which it forked. Netscape is a significant case of later breaking from standards leading to forking, in the form of HTML extensions. [Newman] Microsoft's Internet Explorer also jumped in with its own nonstandard extensions. But this happened after the Web had already gained enough inertia to have a strong user and developer base.
One example of forking away from Gopher too early is Panda, developed by twelve developers at the University of Iowa. Panda was a single, integrated client to the Internet. It handled Gopher, FTP, UseNet, World-Wide-Web, and a host of other protocols. It included custom servers for the Internet, including a Raccoon conferencing server (an overblown BBS server), an Aardvark account management server, and a Parrot multi-user real-time conferencing server. Lee Brintle founded Project Panda, Inc as a non-profit company in fall of 1992, and it lasted until June of 1995. [Brintle, personal homepage], [Brintle, "Panda"] Nothing was contributed back to the Gopher project.
HTTP, on the other hand, got buy-in from the computer world before Mosaic was released, thus preventing the forking that Gopher experienced. The Web's technology was also quickly opened up to the larger development community. In 1994, any control CERN had over the project was quickly abandoned. The CERN Council approved the construction of the LHC accelerator. This Large Hadron Collider made it impossible for CERN to continue deep involvement in the Web technological development. [Cailliau]
In addition to not effectively distributing its development efforts through code sharing, the Gopher team also did not play the Internet standards game as well as the Web community did. Formally established in January of 1986, the Internet Engineering Task Force (IETF) is the protocol engineering and development arm of the Internet. In order to garner mind share among the development community, it is important to take part in the IETF's procedures, including the publication of Internet-Drafts and Requests for Comment (RFCs). This process allows the wider community to critically review the development process. The Gopher team did release a Request for Comments (#1436) in 1993 [Anklesaria, et al] but it was informational, not standards-track. And they failed to follow up on this RFC with publications of additional proposed changes to Gopher.
As mentioned above, instead of attending more general meetings, the Gopher community also split off, holding its own GopherCon'92 conference [Riddle] attended by 50 people. This was a positive step, but it simply did not foster the mind share that would have been possible through participation in wider development community events.
* When interpreting Internet traffic statistics, it is important to remember that navigating the Web generally involves many more data objects (HTML files, images, and numerous other inline inclusions) than does navigating Gopherspace. Usage statistics based on either packets or bytes transferred will thus tend to overestimate the use of the Web and underestimate the use of Gopher. It is important to remember, however, that these NSF statistics were often cited during the period addressed in this paper. Even if they are not completely accurate in their reflection of Internet usage, these statistics contributed to the public perception that the Web was taking the place of Gopher. [Return to text]
Anklesaria, Farhad, et al. "The Internet
Gopher Protocol (a distributed document search and retrieval protocol)."
Request for Comments 1436. March 1993. ftp://ftp.isi.edu/in-notes/rfc1436.txt
Axelrod, Robert and Cohen, Michael Cohen. Harnessing Complexity. Draft, September 1998.
Bauer, Martin."Resistance to new technology and its effects on nuclear power, information technology and biotechnology." In Resistance to New Technology: Nuclear Power, Information Technology and Biotechnology. Edited by Martin Bauer. New York: Cambridge University Press, 1997. 1-41
Berners-Lee, Tim. "The World Wide Web: Past, Present and Future." August 1996. http://www.w3.org/People/Berners-Lee/1996/ppf.html
Brintle, Lee. "Panda." In alt.gopher. 5 May 1992. Archived at http://www1.lu.se/msdosftp/network/winsock/compound/panda/general.txt
Brintle, Lee. Personal Homepage. http://www.leepfrog.com/~lbrintle/
Brown Computer Solutions. "Web Words - Gopher." Last updated 5 August 1996. http://www.browncs.com/gopher.html
Bush, Vannevar. "As We May Think." Atlantic Monthly 176 (1945): 101-8.
Caillliau, Robert. "A Short History of the Web." November 1995. http://www.inria.fr/Actualites/Cailliau-fra.html
Campbell-Kelly, Martin and Aspray, William. Computer: A History of the Information Machine. New York: Basic Books, 1996.
College of Lake County. "Gopher - Introduction." Last updated 16 January 1998. http://www.clc.cc.il.us/home/com589/gopher.htm
Dawkins, Richard. The Blind Watchmaker. New York: W.W. Norton, 1987.
Dawkins, Richard. The Selfish Gene. Oxford: Oxford University, 1976.
Dennet, Daniel Dawin's Dangerous Idea: Evolution and the Meanings of Life. New York: Touchstone, 1996.
Dervin, Brenda. "Chaos, Order, and Sense-Making: A Proposed Theory for Information Design." Draft. 6 March 1995. http://edfu.lis.uiuc.edu/allerton/95/s5/dervin.draft.html
Digital Equipment Corporation. "Sharing File Services Across UNIX and Windows NT." http://www.digital.com/allconnect/acwp1.htm
"FTP/Gopher Servers." ServerWatch. Updated daily as of this writing. http://serverwatch.internet.com/ftpservers2.html
Gabriel, Richard P. "Lisp: Good News, Bad News, How to Win Big." 1991. http://www.naggum.no/worse-is-better.html
Georgia Institute of Technology, Graphics, Visualization & Usability Center. " NSFNET Backbone Traffic Distribution by Service." April 1995. http://www.cc.gatech.edu/gvu/stats/NSF/9504.html
"gopher." In PC Webopaedia. Last modified 19 June 1997. http://webopedia.internet.com/TERM/g/gopher.html
Hafner, Katie and Lyon, Matthew. Where Wizards Stay up Late: The Origins of the Internet. New York: Simon & Schuster, 1996.
Hansen, Mikael. "The Internet: culture, computer, gopher." Last updated 26 March 1996. http://www.dnai.com/~meh/interviews/gopher/english/
Howe, Walt. "A Brief History of the Internet." Last updated 24 October 1998. http://www0.delphi.com/navnet/faq/history.html#gopher
Howe, Walt. "What is a Gopher?" Delphi FAQs. Last updated 22 June 1998. http://www0.delphi.com/navnet/faq/gopher.html
Internet Engineering Task Force http://www.ietf.org
Internet Society. http://www.isoc.org/
Khare, Rohit. "Who Killed Gopher? An Extensible Murder Mystery." 23 December 1998. http://www.ics.uci.edu/~rohit/IEEE-L7-http-gopher.html
Kuhlthau, Carol C. "Information Needs and Information Seeking." 16-17 February 1996. http://www.gslis.ucla.edu/DL/kuhlthau.html.
Levy, Steven. Hackers: Heroes of the Computer Revolution. New York: Dell, 1984.
Lynch, Aaron. Thought Contagion: How Belief Spreads Through Society. New York: BasicBooks, 1996.
MacKay, Charles. Extraordinary Popular Delusions and the Madness of Crowds. London: Richard Bentley, 1841.
MacKenzie, Donald. "Economic and Sociological Explanations of Technological Change." In Knowing Machines. Cambridge, MA: MIT Press, 1996.
Maturana, H. and Varela, F. Autopoiesis and Cognition: The Realization of the Living. Dordecht, Holland: D. Reidel, 1980.
Misa, Thomas J. "Retrieving Sociotechnical Change from Technological Determinism."
National Center for Supercomputing Applications. http://www.ncsa.uiuc.edu/ncsa.html
Newman, Nathan. "The Origins and Future of Open Source Software: A NetAction White Paper" 1999. http://www.netaction.org/opensrc/future/
Pitkow, James E. "Third Degree Polynomial Curve Fitting for Bytes Transferred Per Month By Service." Georgia Institute of Technology, Graphics, Visualization & Usability Center. http://www.cc.gatech.edu/gvu/stats/NSF/Extrap.GIF
Pitkow, James E. "Relation Between Bytes & Packets Transferred Per Month By ServiceThird Degree Polynomial Curve Fitting for Bytes Transferred Per Month By Service." Georgia Institute of Technology, Graphics, Visualization & Usability Center. http://www.cc.gatech.edu/gvu/stats/NSF/Both.GIF and http://www.cc.gatech.edu/gvu/stats/NSF/BothP.GIF
Pitkow, James E. and Recker, Margaret M. "Results From The First World-Wide Web User Survey." Georgia Institute of Technology, Graphics, Visualization & Usability Center. http://www.cc.gatech.edu/gvu/user_surveys/survey-01-1994/survey-paper.html
Pitkow, James E. and Recker, Margaret M. "Results From The Third World-Wide Web User Survey." Georgia Institute of Technology, Graphics, Visualization & Usability Center. http://www.cc.gatech.edu/gvu/user_surveys/survey-04-1995/
Pitkow, James E. and Recker, Margaret M. "Results From The Fourth World-Wide Web User Survey." Georgia Institute of Technology, Graphics, Visualization & Usability Center. http://www.cc.gatech.edu/gvu/user_surveys/survey-10-1995/
Pitkow, James E. and Recker, Margaret M. "Results From The Fifth World-Wide Web User Survey." Georgia Institute of Technology, Graphics, Visualization & Usability Center. http://www.cc.gatech.edu/gvu/user_surveys/survey-04-1996/
Powell, James. "Adventures with the World Wide Web: Creating a Hypertext Library Information System." Database (February 1994): 59-60, 62-66.
Raymond, Eric. "The Cathedral and the Bazaar." 22 November 1998 (with numerous revisions since). http://www.tuxedo.org/~esr/writings/cathedral-bazaar/
Raymond, Eric. "How to Become a Hacker." Last updated 26 March 1999. http://www.tuxedo.org/~esr/faqs/hacker-howto.html
Raymond, Eric, ed. The New Hacker's Dictionary. Version 4.0.0. http://www.tuxedo.org/~esr/jargon/jargon_22.html#SEC29
Reid, Robert H. Architects of the Web: 1,000 Days that Built the Future of Business. New York: John Wiley & Sons, 1997.
Riddle, Prentiss. "GopherCon '92: Trip report." In comp.infosystems.gopher. 17 August 1992. Archived at http://iubio.bio.indiana.edu:70/R0-22906-/IUBio-Software+Data/util/gopher/gophercon1.txt
Salus, Peter H. Casting the Net: From ARPANET to Internet and Beyond. Reading, MA: Addison-Wesley, 1995, 230.
Serdar, Cenk. "Gopher." In Internet Tutorial for the Wharton MBA Program. 3 August 1995. http://opim.wharton.upenn.edu/~serdar93/internet/gopher.html
Simmonds, Curtis. "Searching Internet Archive Sites with Archie: Why, What, Where, and How." Online (March 1993): 50, 52-5.
Sonnenreich, Wes. "A History of Search Engines." Last updated 3 April 1998. http://www.wiley.com/compbooks/sonnenreich/history.html
Stallman, Richard. "The GNU Manifesto." 1985. http://www.fsf.org/gnu/manifesto.html
Stoltz, Mitch. "The Case for Government Promotion of Open Source Software: A NetAction White Paper." 1999. http://www.netaction.org/opensrc/oss-whole.html
Treese, Win. The Internet Index 1 (8 July 1993, revised 7 January 1994). http://www.openmarket.com/intindex/93-12.htm
Treese, Win. The Internet Index 2 (2 August 1994). http://www.openmarket.com/intindex/94-08.htm
Treese, Win. The Internet Index 3 (17 September 1994, revised 19 September 1994). http://www.openmarket.com/intindex/94-09.htm
Treese, Win. The Internet Index 5 (31 December 1994). http://www.openmarket.com/intindex/94-12.htm
Treese, Win. The Internet Index 7 (28 April 1995). http://www.openmarket.com/intindex/95-04.htm
Treese, Win. The Internet Index 22 (31 May 1998). http://www.openmarket.com/intindex/98-05.htm
University of Houston Gopher. gopher://info.lib.uh.edu:70/
University of Minnesota Gopher. gopher://tc.umn.edu:70/
Waldrop, M. Mitchell. Complexity: The Emerging Science at the Edge of Order and Chaos. New York: Simon & Schuster, 1994.
Wilson, Chris and Mittelhauser, Jon. "Developing Global HyperMedia: The NCSA Mosaic System." Proceedings of ACM Hypertext'93, Demonstrations (1993): 13.
Wilson, David L. "Portals seen as huge money maker, but some aren't so sure." San Jose Mercury News (28 June 1998).http://www1.sjmercury.com/business/center/portal062998.htm
Winograd, Terry and Flores, Fernando. Understanding Computers and Cognition: A New Foundation for Design. Reading, MA: Addison-Wesley, 1987.
World Wide Web Consortium. http://www.w3.org/
{kind=link}
{kind=link}
{kind=link}